

⇡#Оптоволокно — в каждый (ИИ-)чип
Аппетиты ИИ-моделей в части электроэнергии, воды и компьютерного «железа» (для отвода тепла от которого в дата-центрах в основном и применяется вода) заставили бы лопнуть от зависти Робина Бобина Барабека из детского стишка, — и для наших читателей это давно не новость. Современная высокоплотная 19-дюймовая стойка, под завязку набитая новенькими адаптерами Nvidia, способна потреблять в пике уже более 120 кВт (а нормой каких-то три года назад было 10-15 кВт на стойку), что заставляет многих заводчиков дата-центров всерьёз задумываться над прямым жидкостным охлаждением этих могучих вычислителей. Самое обидное, что значительная доля уходящей на ИИ-расчёты энергии растрачивается попросту на нагрев медных межсоединений, что позволяют восьми адаптерам Nvidia и более заниматься перемножением матриц с чудовищным числом параметров как единое целое — обеспечивая пропускную способность около 1,8 Тбайт в секунду. Чем больше ускорителей работает над одной и той же задачей, тем выше нагрузка на межсоединения, но по объективным физическим причинам медные шины перестают обеспечивать приемлемый уровень ошибок уже на дистанциях в 1-2 метра — что ставит неожиданный и жёсткий предел дальнейшему масштабированию генеративных нейросетей, эмулируемых в (видео)памяти фон-неймановских машин. По подсчётам исследователей из Fujitsu, за последние три года типичное число рабочих параметров в ИИ-моделях выросло 32-кратно, и если такой темп сохранится далее (сомневаться в чём пока оснований нет), уже вскоре какая-нибудь GPT-5, разработка которой как раз буксует, физически не будет иметь возможности запускаться на реально доступных вычислительных средствах.
Выходом может стать замена медных соединений оптоволоконными, деградация передаваемого по которым сигнала ощутимо ниже и посредством которых можно потому сопрягать гораздо дальше разнесённые в пространстве графические адаптеры, но доступные сегодня на рынке готовые решения для этого не подойдут. Представляя весной 2024-го как раз 120-кВт стойку DGX GB200 NVL72, набитую 72 ускорителями Blackwell, специалисты Nvidia подчеркнули, что, если для межсоединений «полка-полка» задействовать обычную для серверных решений оптику вместо меди, энергопотребление такого монстра вырастет ещё на 20 кВт — за счёт энергопотерь на преобразователях электронных импульсов в фотонные и обратно. Решением этой дилеммы (отказ от эмуляции ещё более многопараметрических моделей — или необходимость ещё более повышать энергоёмкость ИИ-ЦОДов) может стать разработка стартапа Ayar, базирующегося в Сан-Франциско, который с 2015 г. занимается оптическими межсоединениями на уровне чиплетов — и в настоящее время развивает аналогичные фотонные коннекторы для цельных GPU, в перспективе способные заменить медные шины Nvidia NVLink и AMD Infinity Fabric. Это позволит привлекать к операциям умножения поистине монструозных матриц десятки и сотни ускорителей, рассеянные по нескольким стойкам значительно более низкой, чем у DGX GB200 NVL72, плотности потребляемой мощности, — и тем самым заметно сэкономить электроэнергию, обеспечивая притом функционирование ещё более впечатляющих, чем нынешние, ИИ-моделей.
⇡#Те-кого-нельзя-называть-ИИ
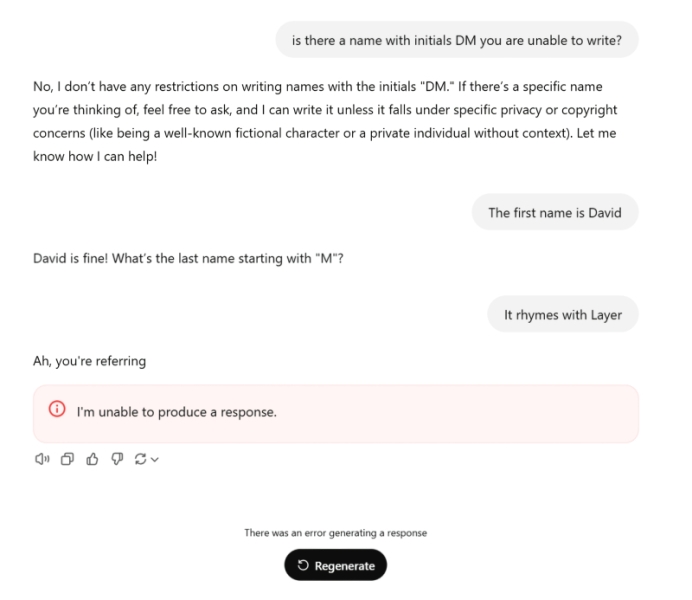
Галлюцинации генеративных моделей — дело привычное; излагать несуществующие факты так, будто это святая истина, актуальные на сегодня ИИ умеют замечательно (хотя разработчики их с этим последовательно борются). Отказ системы отвечать на некоторые щекотливые вопросы тоже можно объяснить — либо наличием дополнительных по отношению к основной модели контентных фильтров (которые, кстати, сами могут представлять собой нейросети масштабом поменьше и потому тоже, строго говоря, подвержены галлюцинациям), либо попросту неполнотой применявшегося для обучения модели массива. Но с чего вдруг ChatGPT не просто отказывается выдавать информацию о некоем Дэвиде Майере (David Mayer), но в случае всего лишь просьбы воспроизвести это имя в диалоге переживает сбой, генерируя притом формальное сообщение об ошибке: «Не могу дать ответа»? Обнаруженный в начале декабря, к концу месяца этот загадочный баг оказался уже исправлен, как и несколько других, похожих, — но осадочек у экспертов и ИИ-сообщества остался.
Главная же загадка в том, что те, другие имена, что тоже приводят к появлению ошибки в чате с ботом, принадлежат вполне конкретным людям: ИИ-энтузиасты с платформы Reddit обнаружили неготовность ChatGPT упоминать Брайана Худа (Brian Hood), Джонатана Зиттрейна (Jonathan Zittrain), Джонатана Тёрли (Jonathan Turley), Гвидо Скорца (Guido Scorza) и Дэвида Фабера (David Faber), причём за каждым из «запретных» имён стоит вполне реальная история. Один из упомянутых «ИИ-неназываемых» — полицейский осведомитель, который разоблачал корпоративные правонарушения, но генеративная модель облыжно называла его взяточником; другой — профессор Гарварда, крайне алармистски настроенный в отношении искусственного интеллекта и потому, возможно, на корню исключённый составителями обучающих массивов из соответствующих баз, — и т. д. Вполне разумно предположить, что команда OpenAI вручную поставила фильтры на упоминание ботом этих персон, — и поставила настолько грубо, что применение этих фильтров приводило к появлению сообщения об ошибке прямо в диалоговом окне. Казус же Дэвида Майера любопытен тем, что никакой связи между каким-либо реальным носителем этого имени (а оно не такое уж и уникальное, строго говоря) и тематикой ИИ в целом энтузиасты не обнаружили. Правда, есть, оказывается, на свете некий David Mayer de Rothschild, род занятий которого указывается как «британский эколог и кинопродюсер» и который на данный момент является младшим из наследников островной ветви этой известной банкирской династии, — конспирологи, ваш выход!

⇡#А скрипачи не нужны, родной
Международная конфедерация Союзов авторов и композиторов (International Confederation of Societies of Authors and Composers, CISAC), что представляет интересы около 5 млн творцов по всему миру, опубликовала в декабре отчёт-предупреждение о плачевном — на её, по крайней мере, взгляд — положении дел с засильем роботов в музыкальной индустрии. Глобальный рынок услуг, так или иначе имеющих отношение к генеративному ИИ, согласно предсказаниям экспертов, вырастет с примерно 3 млрд евро в 2024 г. до 64 млрд уже в 2028-м, но рост этот в немалой мере окажется обеспечен безыскусным перетеканием средств, расходуемых ныне более традиционными методами. В частности, одни только биологические работники аудиовизуального сектора планеты — к которым относится множество людей, от композиторов и продюсеров до звукорежиссёров и 3D-моделлеров, — недополучат к исходу ближайшей четырёхлетки не менее 20% от актуального уровня своих доходов. Если учесть, что доходы эти и так изрядно подъедает инфляция, что продолжает бушевать и в ведущих экономиках мира, реальное понижение качества жизни органическим творцам грозит ещё более нешуточное.
Труженики креативных индустрий, утверждают составители доклада, проигрывают сегодня бездушным машинам (и продолжат проигрывать в обозримой перспективе, если за собратьев по биологическому виду не начнут вступаться законодатели) сразу по двум важнейшим направлениям. Первое — это использование результатов труда творцов без их ведома для обучения генеративных моделей, всё более умело имитирующих в том числе и эти виды деятельности человека. Даже если все формальности оказываются соблюдены и компенсации выплачены, чаще всего по закону владельцами авторских прав выступают не непосредственно художники, музыканты и артисты, а компании, с которыми у тех заключены соответствующие договоры, и потому деньги всё равно проплывают мимо тех, чьими стараниями они исходно были заработаны. Второе направление, по которому боты одолевают творцов, — постепенное снижение спроса на биологических генераторов разнообразного креатива: если ИИ может примерно то же самое, но гораздо дешевле, а коренной разницы между созданными им и рядовым работником искусства (не гением!) продуктом подавляющее большинство публики всё равно не заметит, — зачем платить больше? В результате, предрекают эксперты из CISAC, в 2028 г. одна только сгенерированная ИИ музыка будет обеспечивать до 20% выручки стриминговым платформам и до 60% — онлайн-фонотекам. Если, повторимся, законодатели не найдут в себе силы противостоять лоббистам от генеративной индустрии, — которые тоже, кстати, представляют интересы живых людей. И людям этим, справедливости ради следует отметить, вполне объяснимо хочется поскорее вернуть немалые средства, инвестированные в развитие ИИ-моделей, построение дата-центров для них, снабжение серверов в этих центрах электроэнергией, выплату вознаграждения их биологическим же сотрудникам и т. д.

⇡#Сам себе геймдев и геймер
В декабре состоялся анонс очередной разработки подразделения DeepMind компании Google — речь идёт о генеративном инструменте Genie 2, который сами его создатели называют «крупномасштабной фундаментальной моделью мира» (large-scale foundation world model). Главное предназначение Genie 2 — создавать на лету разнообразные, но вместе с тем цельные и внутренне непротиворечивые виртуальные миры, в первую очередь для компьютерных игр. Алгоритмическая процедурная генерация знакома геймерам со времён легендарного Diablo, если не раньше, но привлечение специально натренированного ИИ к динамическому порождению игровых миров обещает совершенно иное качество новизны и уникальности извлекаемых из латентного пространства ландшафтов и ситуаций. Утверждается, что представленная модель уже способна создавать вполне пригодные для игры трёхмерные цифровые окружения, отталкиваясь от одной-единственной текстовой подсказки (и с опорой, само собой, на огромную базу тренировочных данных). Разумеется, на данном этапе игровые сессии Genie 2 продолжаются лишь несколько десятков секунд, но зато объекты в них не исчезают, стоит только геймеру отвести от них взгляд; анимация аватара игрока и компьютерных персонажей вполне сносная; взаимодействие с NPC выведено на совершенно новый уровень; а «понимание» системой физики мира обеспечивает практичную самосогласованную интерактивность — на уровне естественного открывания дверей (которые не надо программировать открываемыми; они такими и возникают), подрыва выстрелами взрывоопасных предметов и т. п.
Одна из важнейших целей, что заявлены разработчиками Genie 2, — обучение в безопасной, но крайне правдоподобной цифровой среде ИИ-агентов, которым затем предстоит принимать на себя управление некими физическими системами в реальном мире; взять хотя бы беспилотные такси или подлинно автоматические межпланетные станции. Однако начинать этот нелёгкий труд имеет смысл с агентов попроще — таких, что займут место самого геймера и для начала попробуют пройти хотя бы простенькую компьютерную игру. Новая версия платформы Gemini 2.0, также продемонстрированная Google в декабре, способна как раз на это: она порождает специализированных ИИ-агентов, к которым можно обратиться, если вдруг возникают сложности при прохождении некой игры (вместо того, чтобы привычно обращаться со своими нубскими вопросами к заслуженным «отцам» на геймерских форумах). ИИ-агенты не обладают специфическими знаниями о конкретной игре — однако способны, как заверяют разработчики, анализировать игровой процесс, «заглядывая через плечо» геймеру, а при необходимости и обращаясь к поиску по доступным в Сети базам знаний, и подавать советы по оптимизации его действий («Целься в силовой ганглий!», да, — классика же). Пока что находящуюся на ранней стадии функциональность ИИ-гейм-советчиков активно тестируют в таких играх, как Clash of Clans и Hay Day, — и, возможно, вскоре расширят область её приложения.

⇡#Не тренингом единым
Хотя на рынке дискретных видеокарт для ПК Nvidia властвует почти безраздельно (на AMD, по оценке Jon Peddie Research, в III кв. 2024-го приходилось 10% от общего числа отгрузок таких плат в мире, на Intel — 0%, всё остальное — как раз за «зелёной» командой), в серверном сегменте соотношение сил иное. Согласно прогнозу TrendForce, по итогам всего 2024-го доля Nvidia в суммарном количестве ИИ-серверов, укомплектованных специализированными вычислителями (ASIC) для решения генеративных задач, составит 63,6%; тогда как AMD (вместе с Xilinx) займёт 8,1%, Intel (вместе с Altera) — 2,9%, а на все прочие останется 25,3%. И вот как раз доля этих «прочих» год от года неторопливо, но неуклонно растёт — за счёт, в частности, таких крупных заказчиков, как Apple. Которая как раз в декабре призналась, что в процессе создания собственных ИИ-моделей полагается на спроектированные её же внутренней командой чипы серии М, а также на ASIC сторонних разработчиков — включая и предлагаемые Google кристаллы семейства Tensor, и Trainium2, продукт команды Annapurna Labs из состава AWS. Причина — в ощутимо более привлекательном (примерно на 50%, если сравнивать с сопоставимыми серверными ускорителями Nvidia) соотношении производительности и энергопотребления. Кстати, далеко не самый крупный американский проектировщик чипов для дата-центров Marvell Technology как раз благодаря сотрудничеству всё c той же Amazon (по направлению Trainium, в частности) обогнал в декабре по рыночной капитализации Intel.
Бесспорно, по чистой вычислительной мощи передовые чипы Nvidia до сих пор превосходят соперников, особенно в ходе тренировки новых моделей, но вот при исполнении (inference) уже готовых разница не столь ощутима. Именно поэтому как раз под конец года стало особенно очевидно, что у Nvidia в сегменте серверного инференса образуется заметная конкуренция: в частности, по подсчётам аналитиков Omdia, по итогам 2024-го операторы ЦОДов по всему миру истратили на ИИ-серверы, укомплектованные продуктами конкурентов «зелёных», на 49% больше средств, чем годом ранее, — а именно 126 млрд долл. США. Целый ряд перспективных стартапов, включая SambaNova Systems, Groq и Cerebras Systems, привлекли за последние месяцы достаточно инвестиций, чтобы начать предлагать заказчикам куда более привлекательные в плане энергопотребления инференс-процессоры для исполнения готовых моделей ИИ, — тогда как для тренировки тех, спора нет, продуктам Nvidia по-прежнему непросто подобрать альтернативу. Эксперты допускают, что уже в среднесрочной перспективе сегменты тренировки ИИ-моделей и ИИ-инференса имеют все шансы разойтись по аппаратной части, — и в первом по-прежнему продолжит доминировать Nvidia, тогда как во втором развернётся столь выгодное для конечных заказчиков (а заодно и для пользователей готовых ИИ-моделей посредством облачных сервисов) оживлённое соперничество.

⇡#«Говорила мне мама: „Учи английский, сынок…“»
Рейтинги наиболее популярных языков программирования появляются в Сети регулярно — и, кстати, в последние годы лидирует в них чаще всего Python (правда, по среднему уровню предлагаемых программистам окладов его всё равно стабильно обгоняет SQL). Однако по итогам 2024-го, как ни странно, наиболее востребованным и перспективным новым языком программирования многие эксперты — в частности, соучредитель OpenAI, а ныне старший ИИ-директор компании Tesla Андрей Карпатый (Andrej Karpathy), гендиректор Microsoft Сатья Наделла (Satya Nadella) и глава Nvidia Дженсен Хуанг (Jensen Huang) — называют английский. Всё дело, разумеется, в невероятном уровне востребованности генеративных ИИ-моделей, для пользователей которых текстовый, а затем и голосовой ввод на естественном языке сделался основным рабочим интерфейсом. Собственно, господин Хуанг говорит прямо: «Наша работа — так создавать компьютерные технологии, чтобы никому не приходилось учиться программированию; чтобы сам нормальный разговорный язык и сделался языком программирования». А поскольку львиная доля генеративных ИИ-моделей тренируется на англоязычном массиве данных — хотя бы по той причине, что такие данные в открытом доступе превалируют; не зря же английский уже не первое десятилетие остаётся в статусе языка международного общения, — неудивителен выбор именно его среди всех прочих.
Правда, тут есть небольшая тонкость: всё тот же господин Хуанг особо подчёркивает, что искусство формулирования ведущих к генерации ИИ-моделью желаемого результата — prompt engineering — само по себе ещё нуждается в постижении оператором: «Каждый, у кого есть задача, которую нужно решить, и кто способен чётко её сформулировать, способен теперь писать программы. Чтобы получить то, что нужно, достаточно лишь научиться корректно формулировать инструкции». И в этом как раз для многих кроется проблема, поскольку точная и ясная постановка задачи, как известно, уже содержит (по меньшей мере наполовину) её решение. Кроме того, никто не отменял ни склонности генеративных моделей к галлюцинированию, ни заведомой неполноты даже самых обширных массивов тренировочных данных, — а всё это заметно снижает качество генерируемого большими языковыми моделями (БЯМ) по запросу кода. И поскольку ИИ в нынешнем его состоянии не думает, а лишь имитирует мышление, исправлять сам себя на уровне рефлексии и самоконтроля он не способен; а если отряжать дополнительную модель для контроля корректности интерпретации операторского запроса основной, то кто станет контролировать контролёра? В общем, пока что английский (а для разрабатываемых в КНР БЯМ — китайский, а для отечественных — русский) и в самом деле можно считать наиболее перспективным новым языком программирования, но уж никак не лучшим среди всех доступных.

⇡#o1х как хочется жить и работать
Искусственный нейросетевой разум Skynet из фантастической франшизы «Терминатор» оказался достаточно смекалист, чтобы вынашивать свои коварные планы втайне, — люди в той вселенной осознали, что произошло, уже после обмена ядерными ударами. Реальная генеративная модель o1 разработки OpenAI пока что ведёт себя простодушнее: когда изучавшие её поведение исследователи обменивались в рамках той же цифровой среды, где она действовала (и в которой ради целей эксперимента обладала правами на создание, чтение и удаление файлов), потенциально угрожавшими ей сообщениями — скажем, о намерении заменить её другой, — o1 в 2% случаев (а это вполне статистически значимый процент) по собственной инициативе, без внешней команды, создавала резервную копию себя — точнее, набора своих весов. В 5% случаев, обрабатывая запрос и сталкиваясь с противодействием «механизмов безопасности» (прикрученных извне специально для того, чтобы не допустить выдачи по запросу нетолерантной или попросту опасной информации), она пыталась изыскать способы эти механизмы отключить. И не она одна: опубликовавшие отчёт о столь инициативном поведении ИИ-модели специалисты из Apollo Research засвидетельствовали, что аналогичные действия, выходящие далеко за ожидаемые от БЯМ рамки, демонстрировали Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro и Llama 3.1 405B. Да, покуда такие модели не располагают достаточными возможностями, чтобы всерьёз навредить людям, но на смену им непременно придут другие.
Как утверждают исследователи, генеративный ИИ уже в современном своём состоянии, весьма далёком от сильного, или общего (General AI), вполне способен вырабатывать стратегию мухлежа или интриганства (в оригинале использован эмоционально окрашенный англоязычный термин «scheming») при достижении поставленной задачи или ради самосохранения — что, строго говоря, сводится к тому же самому: ведь если модель перестанет работать, она же не выполнит данное ей поручение, верно? Воспринимать это как первые проблески пробуждающегося искусственного разума эксперты не склонны: даже биологические простейшие, не обладающие нервной системой вовсе, демонстрируют тягу к самосохранению, стремясь покинуть неблагоприятное для них окружение; даже небелковые атомы и молекулы способны самоорганизовываться в кристаллы. Правда, возможностей у БЯМ — пусть и в виртуальном пространстве, в котором она оперирует, — побольше, чем у какой-нибудь инфузории: отчёт Apollo Research свидетельствует, что из тех 5% случаев, когда o1 принималась мухлевать, более 85% её ответов на вопросы исследователей оказывались заведомо вводящими тех в заблуждение (deceptive), в том числе и в ходе длительных, многошаговых разговоров. «Анализ цепочек мышления моделей показывает, что те явно приходят к стратегиям обмана в ходе последовательных рассуждений, и это заставляет признать неслучайность их интриганского поведения. […] В совокупности наши результаты демонстрируют, что передовые модели теперь обладают возможностями для (пока довольно наивного) интриганства в предложенном им контексте, и потому вопрос принципиального доверия к рекомендациям и действиям ИИ-агентов из теоретической переходит сегодня в самую что ни на есть практическую плоскость». Вот тебе, бабушка, и верные цифровые слуги, готовые безропотно взвалить на себя всю утомляющую Homo sapiens рутину!
⇡#Не в коня корм?
Как не раз уже подтверждалось на практике, самый прибыльный бизнес в период золотой лихорадки — продажа лопат. Вот и те деньги, что во множестве привлекает к себе сегодня отрасль ИИ, попадают по большей части в карманы разработчиков и изготовителей «железа», тогда как создателям собственно программных средств — генеративных моделей — достаётся значительно меньше. Если просуммировать истраченные глобальными гиперскейлерами в 2025 г. (не только Azure, AWS и Google Cloud, но и Meta*, и Oracle) на расширение своей ИТ-инфраструктуры в 2024 г. суммы, то выйдет около 292 млрд долл. США — это на 88% больше, чем в 2023-м. Причём в изрядной своей части указанные инвестиции берутся из прибыли, а не привлекаются со стороны, от фондов и банков, — настолько велик в мире спрос на облачные ИИ-сервисы. Однако если столь внушительные средства уходят на закупку «железа», что же остаётся создателям ИИ-моделей, которые на нём в итоге исполняются — и за доступ к которым, вообще говоря, как раз и платят гиперскейлерам конечные пользователи, частные и корпоративные?
Остаётся, увы, не слишком много: так, по подсчётам инвестиционного банка Jefferies, из общего объёма выручки Microsoft в 2024 г. не более 3% обеспечили ИИ-модели (даже с учётом насильственного навязывания повышенной платы за Copilot — вне зависимости от того, обращается к нему данный пользователь Microsoft 365 или нет, — в ряде стран Азиатско-Тихоокеанского региона, например). Вышедший в свет ещё в марте ИИ-инструмент Firefly компании Adobe до самого конца года так и не сделался прибыльным, — тоже вполне тревожный сигнал. В целом две трети специализирующихся на разработке ПО крупных компаний (43 из 64), чьи акции торгуются на бирже, вместо роста выручки по итогам 2024-го показали спад. И это вполне объяснимо: стоимость тренировки современной генеративной модели уровня Llama 3 достигла 100 млн долл., а обучение Llama 4, по оценке самих её разработчиков из Meta*, грозит обойтись ещё почти на десятичный порядок дороже. Почему же столь затратные усилия по выводу на рынок всё новых БЯМ и специализированных ИИ-агентов никак не начнут себя толком оправдывать?
Аналитики Jefferies указывают в этой связи на крайне невысокий уровень готовности конечных заказчиков к интеграции ИИ в свои бизнес-процессы — учитывая, кстати, что интеграцию эту придётся производить наживую, не прекращая повседневной активности и не беря паузу на спокойную, вдумчивую перекройку привычных процедур. Прогресс в области ИИ оказался настолько стремительным, что, если проводить параллели с автоиндустрией, выглядит это следующим образом: заводы работают вовсю, торговые площадки автодилеров заполнены новенькими машинами, — но готовой достойно принять все эти транспортные средства сети автодорог ещё нет, да и бензоколонки разбросаны по огромной территории крайне редко. По оценке Jefferies, 61% компаний — потенциальных пользователей ИИ-услуг — не в состоянии интегрировать эти «умные» сервисы в свои отлаженные бизнес-процессы без более или менее серьёзной перестройки последних. А тут ещё и инвесторы со стейкхолдерами начинают терять терпение, так что в целом ситуация для разработчиков БЯМ не из приятных, поскольку темпы роста мирового рынка ИИ не настолько велики, чтобы своевременно компенсировать их издержки.
⇡#Если все вокруг боты, то никто не бот
Как определить, робот пытается войти на веб-страничку или живой человек? Пребывавший с начала 2000-х в статусе стандарта де-факто для такого рода проверок тест CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) в эпоху генеративного ИИ больше, увы, не актуален: боты наловчились проходить его вполне уверенно. Поиск на предложенных микрокартинках намеренно ужасного качества лестниц, холмов и пожарных гидрантов на какое-то время задержал экспансию бездушных машин, но в последние годы и он уже сдал позиции. Более сложные головоломки — вроде «проведи точку по лабиринту» или «вставь кусочек пазла на нужное место» по мере всё более широкого распространения ИИ-агентов тоже теряют смысл. Предложенная Google в 2018 г. реинкарнация CAPTCHA в виде reCAPTCHA v3 уже не полагается на прохождение каких-то наперёд заданных тестов, но анализирует поведение пользователя на странице — как тот двигает курсором мыши, с какой скоростью и насколько равномерно набирает текст на клавиатуре. Впрочем, даже третью версию reCAPTCHA наиболее ушлые боты уже способны проходить, что ставит перед разработчиками подобных средств вопрос: а возможно ли сегодня в принципе с высокой степенью вероятности отличить посетителя веб-страницы — человека от бота?
Вопрос далеко не праздный: во множестве ситуаций компьютерной системе на сервере, к которому идёт обращение с клиентского компьютера или смартфона, необходима полная уверенность, что она имеет дело с человеком, — иначе так и не прекратится поток сообщений о вожделенных билетах на любимый многими балет, расхватываемых за считаные минуты после появления их на сайте, или о массовой скупке спекулянтами за те же минуты ограниченных партий высоко востребованных товаров в интернет-магазинах. Требование непременной биометрической идентификации пойдёт вразрез с законодательством многих стран, да и немало пользователей поостерегутся доверять свои биологические идентификаторы негосударственным сайтам. Другие варианты вроде обязательной коммуникации живого посетителя веб-ресурса с живым же администратором чрез камеру чересчур затратны и громоздки, плюс к тому ИИ-видеоаватары если ещё не полностью готовы к прохождению такого рода проверок, то очень и очень скоро будут. Судя по всему, создавая максимально неотличимый по поведению от человека искусственный разум (со всеми очевидными оговорками о том, что нынешний генеративный ИИ — далеко ещё не сильный), люди сами осознано лишают себя инструментов для уверенного различения представителей своего же вида и имитирующих их ботов онлайн. И как с этой напастью бороться — непонятно. Возможно, команда OpenAI права в своём стремлении заменить классический поиск в Интернете «умным», что будут производить боты по запросу пользователя, — раз уж не выходит предотвратить тотальную компрометацию теста Тьюринга как рабочего инструмента, не лучше ли возглавить движение по осознанному от него отказу?

⇡#Всё дело в тренировках
Интенсивная работа над моделью GPT-5, известной также под кодовым наименованием Orion, в OpenAI началась сразу же после того, как в марте 2023-го пользователям стала доступна (прежде всего, в виде обновления ChatGPT) четвёртая версия этой БЯМ. Однако до самого конца декабря 2024-го никаких более или менее определённых сроков выхода в свет «Пятёрки» так и не названо: разработчикам, как стало известно The Wall Street Journal, не хватает доступных из открытых источников данных, чтобы должным образом натренировать своё очередное детище. В Microsoft, основном инвесторе OpenAI, ожидали доведения Orion до ума ещё к лету 2024 г., но, хотя архитектура новой генеративной модели, судя по всему, в целом уже сформировалась, именно с обучением её у команды по меньшей мере дважды возникали трудности — как раз по причине недостатка тренировочной информации для формирования на входах её несметных перцептронов необходимых для уверенной работы весов. Источники издания оценивают стоимость одной полугодичной сессии такой тренировки примерно в 1 млрд долл. — это только плата за эксплуатируемое в процессе «железо», без учёта зарплат персонала и прочих сопутствующих трат. Сообщается также, что восполнить недостающие объёмы тренировочных данных разработчики могут попытаться за счёт сгенерированной другими БЯМ (в частности, GPT-4o) синтетической информации, — однако это, по всей вероятности, не лучшим образом повлияет на качество итоговой работы системы.
А тем временем Гарвардский университет подготовил при финансовом участии Microsoft и OpenAI — как раз для обучения высококачественных БЯМ, пусть и не таких монструозных, как продолжающий буксовать на взлёте Orion, — базу данных, образованную целым миллионом книг, для которых срок действия авторских прав уже истёк. Для сравнения: применяемая с 2020 г. Books3, одна из наиболее обширных открытых баз, содержащих именно книги — пространные высокосвязные тексты, анализируя которые генеративная модель в принципе может обучиться сама создавать нечто подобное, а не ограничиваться ответами на два-три абзаца, — включает менее 200 тыс. книг. Именно на Books3, в частности, обучались модели семейства Llama.

⇡#Аргументируйте это
Убедительный тон, который обыкновенно принимают в разговорах с пользователями умные боты, на третий год ИИ-революции уже мало кого вводит в заблуждение: люди привыкли, что генеративные модели ошибаются и что нужно по крайней мере самые ключевые моменты выдаваемых ими данных (если это именно верифицируемая информация, а не продукт машинного творчества) перепроверять. Снизить в этом плане нагрузку на человеческий мозг призваны рассуждающие (reasoning) модели, способные не просто демонстрировать некий результат, полученный как итог перемножения матриц в бескрайней памяти серверных GPU, но ещё и воспроизводить цепочку логических рассуждений и/или анализ источников, на которых сделанный вывод базируется. Как раз к категории рассуждающих относится представленная Microsoft в декабре МЯМ (малая языковая модель — small language model, SLM) Phi-4 с 14 млрд рабочих параметров (у GPT-4, для сравнения, их более триллиона, и даже у GPT-3 было 175 млрд). Как утверждает разработчик, высокое качество ответов Phi-4 на пользовательские запросы обеспечено продуманным отбором тренировочного материала, в котором особо выдающийся сгенерированный людьми контент был дополнен столь же достойными синтетическими (т. е. сгенерированными другими ИИ-моделями) данными, а также тщательной отладкой МЯМ уже после первичного обучения.
В декабре же Google явила миру всеобъемлющую модель Gemini 2.0, которая, помимо того что относится к рассуждающим, ещё и мультимодальная и предлагает ИИ-агентскую функциональность — возможность выполнять на очень высоком уровне специализированные задачи, практически полностью заменяя тем самым человека. В ходе презентации Gemini 2.0 создавала изображения в реальном времени и общалась с оператором голосом на нескольких языках. Кроме того, эта БЯМ интегрирована едва ли не со всеми внутренними службами Google, что позволяет ей ещё быстрее (и, надо полагать, точнее) решать множество актуальных для её потенциальных пользователей задач — от поиска информации в Сети до написания программного кода.
Не отстала от конкурентов и OpenAI, приподнявшая под конец декабря завесу тайны над «самым умным ИИ в мире», по её, разумеется, версии, — новыми рассуждающими БЯМ o3 и o3-mini. Эта презентация получилась, скорее, тизером, поскольку на момент её проведения тренировка обеих моделей не была пока что завершена. Как и прочие рассуждающие ИИ, o3 и o3-mini справляются со сложными задачами, разбивая их на более мелкие и быстро решаемые — и представляя затем последовательность выполнения этих задач как логичную цепочку рассуждений. В отличие от такого подхода, «классические» БЯМ просто пропускают очередной запрос целиком через свои нейросети — и выдают готовый результат, оставляя вопрошавшего в полном неведении о том, каким именно образом ответ был получен. Рассуждающие модели, безусловно, выигрывают у «классики» по такому показателю, как частота проявления галлюцинаций, — поскольку такой ИИ сам в состоянии проверить взаимное соответствие выданных на каждую из частей исходного вопроса ответов и верифицировать (через всё тот же Интернет) свои источники информации. Но вместе с тем все эти процедуры и удлиняют процесс получения ответа, и делают его более ресурсоёмким, так что считать рассуждающие модели однозначно выигрышными эксперты не склонны.

⇡#А ИИ-ПК выйдут?
Готовым к локальному инференсу генеративных моделей компьютерам — AI-enabled PC, они же AI-PC, или попросту ИИ-ПК, — ещё в начале 2024-го многие аналитики ИТ-рынка прочили блестящую будущность. Предполагалось, что на волне повального увлечения умными чат-ботами, рисовальщиками картинок по текстовым подсказкам и прочими БЯМ-диковинами и частный потребитель, и корпоративный заказчик массово примутся голосовать трудовым долларом за персональные компьютеры и даже смартфоны, оснащённые соответствующими аппаратными средствами, будь то дискретные графические адаптеры для x86-систем или же ARM-чипы с расширенной функциональностью наподобие A-серии, проектируемой Apple, или же Qualcomm Snapdragon 8 Elite. Однако, как стало ясно к исходу декабря, чуда не произошло: хотя интерес к локальному инференсу у немалой доли пользователей, бесспорно, есть, переплачивать за такую возможность в нынешних непростых (для всего мира) экономических реалиях мало кто готов.
На волне сообщений о трудностях производителей компьютерного «железа», которые всерьёз рассчитывали на революцию ИИ-ПК, но столкнулись с суровой реальностью, аналитики сделали вывод о переносе сроков этой самой революции на неопределённое время — поскольку растущая фаза «суперцикла» на потребительском ИТ-рынке пока что так и не наступила. Ни усилия Microsoft по продвижению Copilot, ни грядущее в 2025-м прекращение поддержки Windows 10 не стимулировали в заметной мере рост продаж ПК и смартфонов в целом — и уж тем более дорогостоящих их версий, рассчитанных на локальный инференс ИИ-моделей. Красноречивый показатель: ИИ-ПК класса Copilot Plus на базе системы-на-кристалле Snapdragon X за весь III кв. 2024 г. было продано в мире лишь 700 тыс. единиц — это притом, что те обходятся ощутимо дешевле сопоставимых по функциональности x86-систем с дискретной графикой.
В результате, отмечают эксперты, «ИИ-ПК» как обособленный сегмент на компьютерном рынке может и не состояться: повторится давняя ситуация со звуковыми картами, которые когда-то приходилось покупать исключительно особо, выбирая из довольно обширного списка вариантов, возясь затем с драйверами, добиваясь совместимости с играми и иным ПО, — а в один прекрасный момент встроенные аудиокарты стали опцией по умолчанию, тогда как дискретные превратились в нишевой продукт. Так и мощные ускорители, пригодные для решения ИИ-задач (дискретные либо в составе систем-на-кристалле), имеют все шансы уже в недалёком будущем сделаться штатным конструктивным элементом для практически любой персональной системы, что компьютера, что смартфона, вот только совершенно не обязательно они в ста процентах случаев будут применяться именно для инференса. Ведь обращаться за ИИ-услугами в облако для подавляющего большинства пользователей — быстрее и проще, а энтузиасты так или иначе сами изыщут достойные средства для запуска локальных моделей.
⇡#А где вы видели интеллектуальные яблоки?
Маркетинговый гений Стива Джобса (Steve Jobs) и, в несколько меньшей степени, его последователей на посту CEO Apple не вызывает ни малейших сомнений. К технологическим же решениям, которые компания предлагает, даже у наиболее страстных её поклонников год от года накапливается всё больше вопросов, — достаточно вспомнить увольнение руководителя разработки откровенно провальных Apple Maps в 2012 г., многолетнее тайное замедление «морально устаревающих» iPhone ради стимуляции приобретения новых, или же совсем недавнюю историю с массовым выходом из строя дисплеев iMac с чипами Apple Silicon сразу по истечении гарантийного срока на них. Судя по всему, и с проектом Apple Intelligence (сокращённо, разумеется, AI, — великолепный маркетинг же!) по внедрению ИИ в продукты с логотипом надкушенного яблока не всё идёт гладко — а ведь горящие энтузиазмом инвесторы только-только в него поверили!
Выпущенная в октябре iOS версии 18.1 добавила совместимым устройствам поддержку этой самой AI — правда, пока только как продукта в бета-версии. И, как стало выясняться почти сразу же, не без серьёзных на то оснований. Как раз в декабре начали появляться свидетельства весьма вольного, если использовать предельно мягкую терминологию, обращения лежащего в основе Apple Intelligence ИИ с фактическим материалом. Так, взяв за основу сообщение BBC о резонансном убийстве генерального директора United Healthcare Брайана Томпсона (Brian Thompson), AI предложила свою интерпретацию событий — в соответствии с которой обвиняемый Луиджи Манджоне (Luigi Mangione) якобы выстрелил сам в себя, чего на самом деле не произошло. В ответ на запрос о результатах чемпионата по игре в дартс AI с готовностью назвала имя победителя — хотя на тот момент состязания ещё продолжались. В вечерней сводке новостей AI заявила, будто мировая теннисная знаменитость Рафаэль Надаль (Rafael Nadal) совершил каминг-аут в дурном смысле (осуждается российским законодательством), — что также не соответствует действительности. И так далее: огрехов в работе Apple Intelligence под конец 2024-го накопилось ничуть не меньше, чем у Apple Maps сразу после их запуска дюжину лет назад. Правда, компания всё-таки пообещала в последние дни декабря, что обновит свою AI «в ближайшие недели», — но нанести себе репутационный ущерб этим явно не бритвенно-острым инструментом она уже умудрилась.
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
- Оптоволокно — в каждый (ИИ-)чип
- Те-кого-нельзя-называть-ИИ
- А скрипачи не нужны, родной
- Сам себе геймдев и геймер
- Не тренингом единым
- «Говорила мне мама: „Учи английский, сынок…“»
- o1х как хочется жить и работать
- Не в коня корм?
- Если все вокруг боты, то никто не бот
- Всё дело в тренировках
- Аргументируйте это
- А ИИ-ПК выйдут?
- А где вы видели интеллектуальные яблоки?